Query-Specific Visual Semantic Spaces for Web Image Re-ranking
Introduction
Image re-ranking, as an effective way to improve the results of web-based image search, has been adopted by current commercial search engines. Given a query keyword, a pool of images is first retrieved by the search engine based on textual information. By asking the user to select a query image from the pool, the remaining images are re-ranked based on their visual similarities with the query image. A major challenge is that the similarities of visual features do not well correlate with images’ semantic meanings which interpret users’ search intention. On the other hand, learning a universal visual semantic space to characterize highly diverse images from the web is difficult and inefficient.
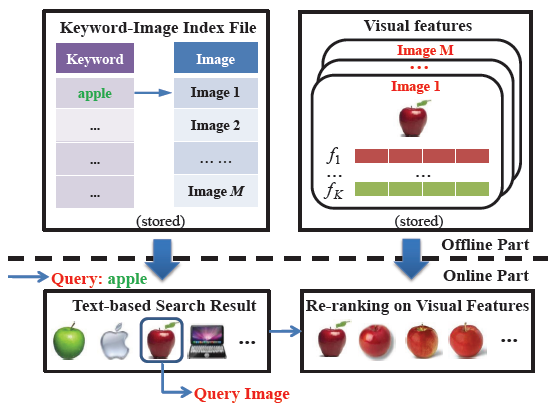
Figure 1. Diagram of the conventional image re-ranking framework.
Our Approach
Instead of constructing a universal concept dictionary, our proposed image re-ranking framework learns different visual semantic spaces for different query keywords individually and automatically. The semantic space related to the images to be re-ranked can be significantly narrowed down by the query keyword provided by the user. For example, if the query keyword is “apple”, the semantic concepts of “mountains” and “Paris” are unlikely to be relevant and can be ignored. Instead, the semantic concepts of “computers” and “fruit” will be used to learn the visual semantic space related to “apple”. The visual features of images are then projected into their related visual semantic spaces to get semantic signatures. At the online stage, images are re-ranked by comparing their semantic signatures obtained from the visual semantic space of the query keyword.
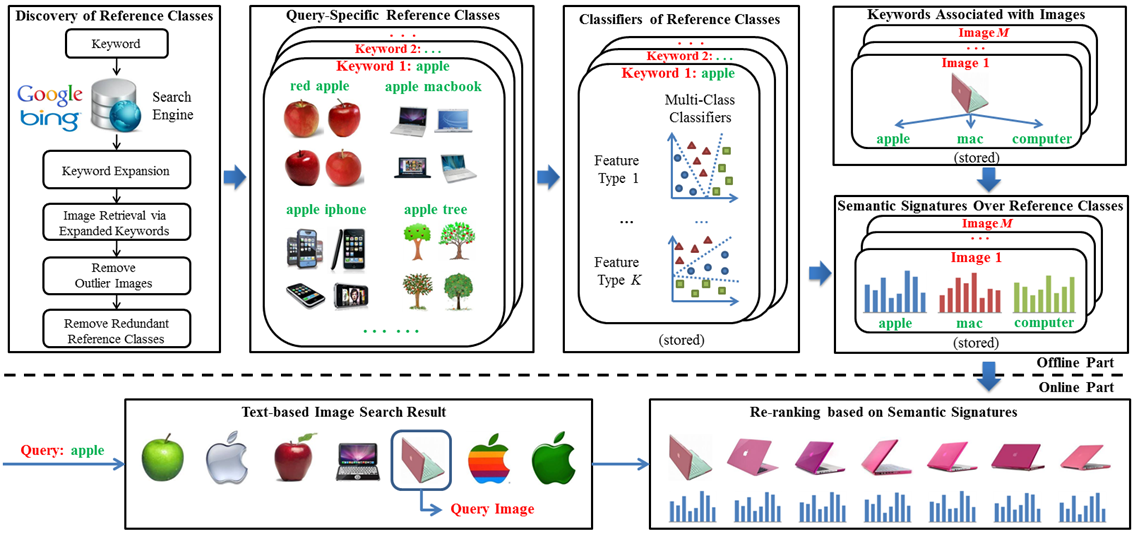
Figure 2. Diagram of our new image re-ranking framework.
The diagram of our approach is shown in Figure 2. At the offline stage, the reference classes of query keywords are automatically discovered from keyword expansions. For a query keyword (e.g. “apple”), a set of most relevant keyword expansions (such as “red apple”, “apple macbook” and “apple iphone”) are automatically selected considering both textual and visual information. The keyword expansion (e.g. “red apple”) is used to retrieve images by the search engine. After removing outliers, the retrieved top images are used as the training examples of the reference class. Some reference classes (such as “apple laptop” and “apple macbook”) have similar semantic meanings and their training sets are also visually similar. Such redundant reference classes are removed for the sake of efficiency.
For each query keyword, a multi-class classifier on low-level visual features is trained from the training sets of its reference classes and stored offline. If there are K types of visual features, one could combine them to train a single classifier, or train a separate classifier for each type of features. Our experiments show that the latter choice can increase the re-ranking accuracy but will also increase storage and reduce the online matching efficiency because of the increased size of semantic signatures. According to the word-image index file, each image in the database is associated with a few relevant keywords. For each relevant keyword, a semantic signature of the image is extracted by computing the visual similarities between the image and the reference classes of the keyword using the classifiers trained in the previous step. The reference classes form the basis of the semantic space of the keyword. If an image has N relevant keywords, then it has N semantic signatures to be computed and stored offline.
At the online stage, a pool of images is retrieved by the search engine according to the query keyword input by a user. Since all the images in the pool are relevant to the query keyword, they all have pre-computed semantic signatures in the semantic space of the query keyword. Once the user chooses a query image, all the images are re-ranked by comparing similarities of the semantic signatures.
More detailed description of this work can be found in [1].
Experimental Results
Data set
As summarized in Table 1, we create three data sets to evaluate the performance of our approach in different scenarios. These data sets can be downloaded here.
Table 1. Descriptions of data sets
|
Data set |
Images for re-ranking |
Images of reference classes |
|||
|
# Keywords |
Collecting date |
Search engine |
Collecting date |
Search engine |
|
|
I |
120 |
Jul-10 |
Bing |
Jul-10 |
Bing |
|
II |
Jul-10 |
|
|||
|
III |
10 |
Aug-09 |
Bing |
Jul-10 |
Bing |
Re-ranking Precisions
Five labelers are invited to manually label testing images under each query keywords into different categories according to their semantic meanings. Averaged top m precision is used as the evaluation criterion. Top m precision is defined as the proportion of relevant images among top m re-ranked images. Relevant images are those in the same category as the query image. Averaged top m precision is obtained by averaging top m precision for every query image (excluding outliers).
We compare with two benchmark image re-ranking approaches used in [2]. They directly compare visual features.
(1) Global Weighting. Predefined fixed weights are adopted to fuse the distances of different low-level visual features.
(2) Adaptive Weighting. [2] proposed adaptive weights for query images to fuse the distances of different low-level visual features. It is adopted by Bing Image Search.
For our new approaches, two different ways of computing semantic signatures are compared.
(3) Query-specific visual semantic space using single signatures (QSVSS_Single). For an image, a single semantic signature is computed from one SVM classifier trained by combining all types of visual features.
(4) Query-specific visual semantic space using multiple signatures (QSVSS_Multiple). For an image, multiple semantic signatures are computed from multiple SVM classifiers, each of which is trained on one type of visual features separately.
The averaged top m precisions on data sets I-III are shown in Figure 3 (a)-(c). Our approach significantly outperforms Global Weighting and Adaptive Weighting, which directly compare visual features. On data set I, our approach enhances the averaged top 10 precision from 44:41% (Adaptive Weighting) to 55:12%
(QSVSS Multiple). 24:1% relative improvement has been achieved. Figure 3 (d) and (e) show the histograms of improvements of averaged top 10 precision of the 120 query keywords on data set I and II by comparing QSVSS Multiple with Adaptive Weighting. Figure 4 (f) shows the improvements of averaged top 10 precision of the 10 query keywords on data set III.
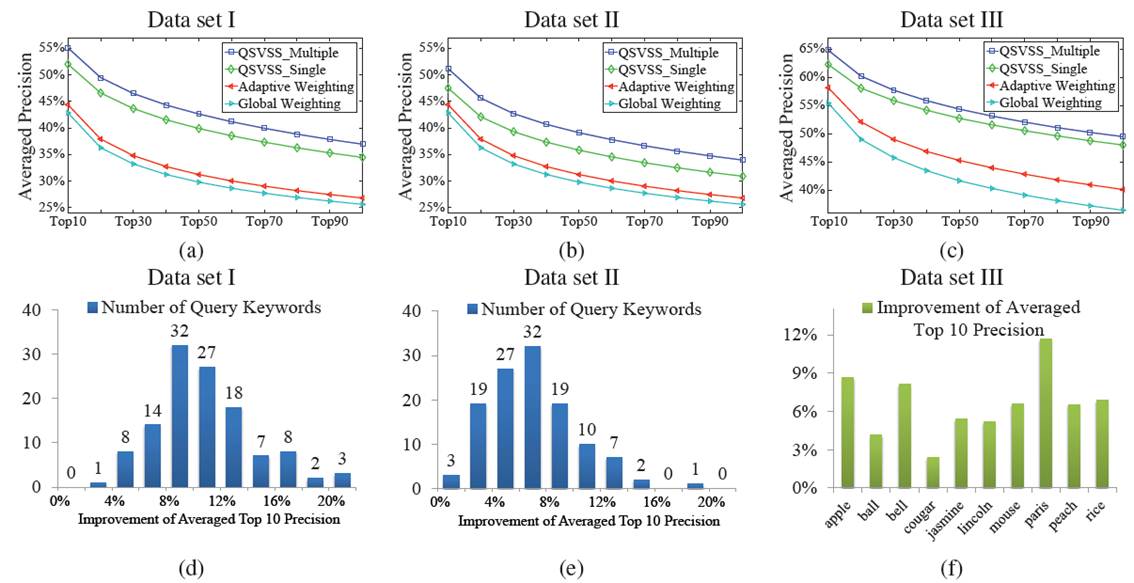
Figure 3. (a)-(c): comparisons of averaged top m precisions on data set I, II, III. (d)-(e): histograms of improvements of averaged top 10 precisions
on data sets I and II by comparing QSVSS Multiple with Adaptive Weighting. (f): improvements of averaged top 10 precisions of the 10 query keywords
on data set III by comparing QSVSS Multiple with Adaptive Weighting.
Sample Results




[1] X. Wang, K. Liu and X. Tang, “Query-Specific Visual Semantic Spaces for Web Image Re-ranking”, in Proceedings of IEEE Computer Society Conference on Computer Vision and Patter Recognition (CVPR) 2011. [PDF].
[2] J. Cui, F. Wen and X. Tang, “Real Time Google and Live Image Search Re-ranking”, in Proceedings of ACM Multimedia, 2008. [PDF]