Deep Convolution Networks for Compression
Artifacts Reduction
Ke Yu, Chao Dong, Yubin Deng, Chen Change Loy, Xiaoou Tang
Department of Informaiton Engineering, The Chinese University of Hong Kong
ericyu16@hotmail.com, dongchao@sensetime.com, {dy015, ccloy, xtang}@ie.cuhk.edu.hk

Abstract
Lossy compression introduces complex compression artifacts, particularly blocking artifacts, ringing effects and blurring. Existing algorithms either focus on removing blocking artifacts and produce blurred output, or restore sharpened images that are accompanied with ringing effects. Inspired by the success of deep convolutional networks (DCN) on superresolution, we formulate a compact and efficient network for seamless attenuation of different compression artifacts. To meet the speed requirement of real-world applications, we further accelerate the proposed baseline model by layer decomposition and joint use of large-stride convolutional and deconvolutional layers. This also leads to a more general CNN framework that has a close relationship with the conventional Multi-Layer Perceptron (MLP). Finally, the modified network achieves a speed up of 7.5x with almost no performance loss compared to the baseline model. We also demonstrate that a deeper model can be effectively trained with features learned in a shallow network. Following a similar "easy to hard" idea, we systematically investigate three practical transfer settings and show the effectiveness of transfer learning in low-level vision problems. Our method shows superior performance than the state-of-the-art methods both on benchmark datasets and a real-world use case.
The proposed models -- AR-CNN and Fast AR-CNN
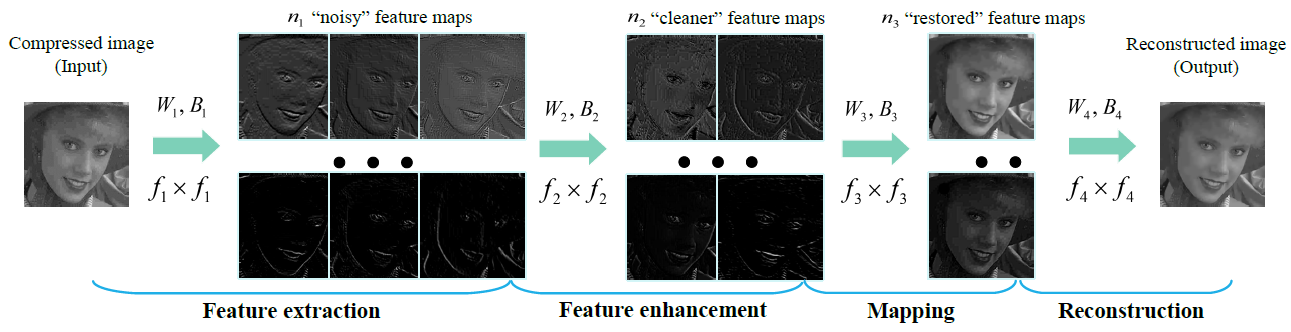
The framework of the Artifacts Reduction Convolutional Neural Network (AR-CNN). The network consists of four convolutional layers, each of which is responsible for a specific operation. Then it optimizes the four operations (i.e., feature extraction, feature enhancement, mapping and reconstruction) jointly in an end-to-end framework. Example feature maps shown in each step could well illustrate the functionality of each operation. They are normalized for better visualization.
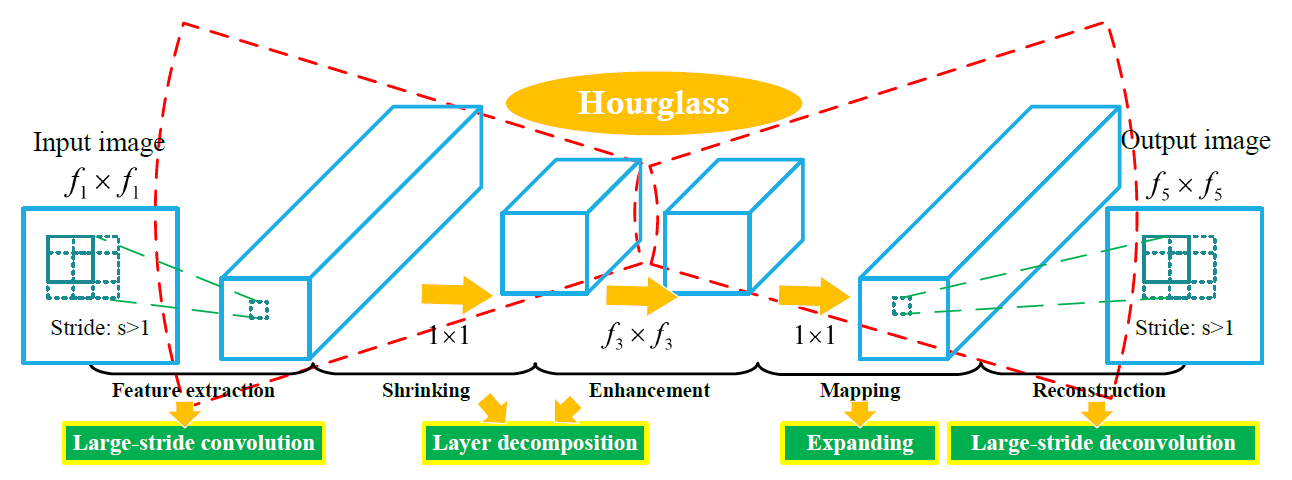
The framework of the Fast AR-CNN. There are two main modifications based on the original AR-CNN. First, the layer decomposition splits the original "feature enhancement" layer into a "shrinking" layer and an "enhancement" layer. Then the large-stride convolutional and deconvolutional layers significantly decrease the spatial size of the feature maps of the middle layers. The overall shape of the framework is like an hourglass, which is thick at the ends and thin in the middle.
Results
The average results of PSNR (dB), SSIM, PSNR-B (dB) on the LIVE1 [1] dataset.
Quality |
JPEG PSNR / SSIM / PSNR-B |
SA-DCT [2] PSNR / SSIM / PSNR-B |
AR-CNN PSNR / SSIM / PSNR-B |
Fast AR-CNN PSNR / SSIM / PSNR-B |
10 |
27.77 / 0.7905 / 25.33 |
28.65 / 0.8093 / 28.01 |
29.13 / 0.8232 / 28.74 |
29.10 / 0.8246 / 28.65 |
20 |
30.07 / 0.8683 / 27.57 |
30.81 / 0.8781 / 29.82 |
31.40 / 0.8886 / 30.69 |
31.29 / 0.8873 / 30.54 |
30 |
31.41 / 0.9000 / 28.92 |
32.08 / 0.9078 / 30.92 |
32.69 / 0.9166 / 32.15 |
32.41 / 0.9124 / 31.43 |
40 |
32.35 / 0.9173 / 29.96 |
32.99 / 0.9240 / 31.79 |
33.63 / 0.9306 / 33.12 |
33.43 / 0.9306 / 32.51 |
The average results of PSNR (dB), SSIM, PSNR-B (dB) on 5 classical test images [2].
Quality |
JPEG PSNR / SSIM / PSNR-B |
SA-DCT [2] PSNR / SSIM / PSNR-B |
AR-CNN PSNR / SSIM / PSNR-B |
Fast AR-CNN PSNR / SSIM / PSNR-B |
10 |
27.82 / 0.7800 / 25.21 |
28.88 / 0.8071 / 28.16 |
29.04 / 0.8111 / 28.75 |
29.03 / 0.8127/ 28.50 |
20 |
30.12 / 0.8541 / 27.50 |
30.92 / 0.8663 / 29.75 |
31.16 / 0.8694 / 30.60 |
31.14 / 0.8697 / 30.22 |
30 |
31.48 / 0.8844 / 28.94 |
32.14 / 0.8914 / 30.83 |
32.52 / 0.8967 / 31.99 |
32.24 / 0.8933 / 31.11 |
40 |
32.43 / 0.9011 / 29.92 |
33.00 / 0.9055 / 31.59 |
33.34 / 0.9101 / 32.80 |
33.14 / 0.9104 / 32.06 |
[1] H. R. Sheikh, Z. Wang, L. Cormack, and A. C. Bovik. "LIVE image quality assessment database release 2." (2005).
[2] A. Foi, V. Katkovnik, and K. Egiazarian. "Pointwise shape-adaptive DCT for high-quality denoising and deblocking of grayscale and color images." TIP on 16.5 (2007): 1395-1411.
Application on Twitter-compressed images
Online Social Media like Twitter are popular platforms for message posting. However, Twitter will compress the uploaded images on the server-side. For instance, a typical 8 mega-pixel (MP) image (3264 x 2448) will result in a compressed and re-scaled version with a fixed resolution of 600 x 450. Such re-scaling and compression will introduce very complex artifacts, making restoration difficult for existing deblocking algorithms (e.g., SA-DCT). However, AR-CNN can fit to the new data easily. We use 40 photos of resolution 3264 x 2448 taken by mobile phones (totally 335,209 training subimages) and their Twitter-compressed version to train a four-layer network. The results are shown as follows.
