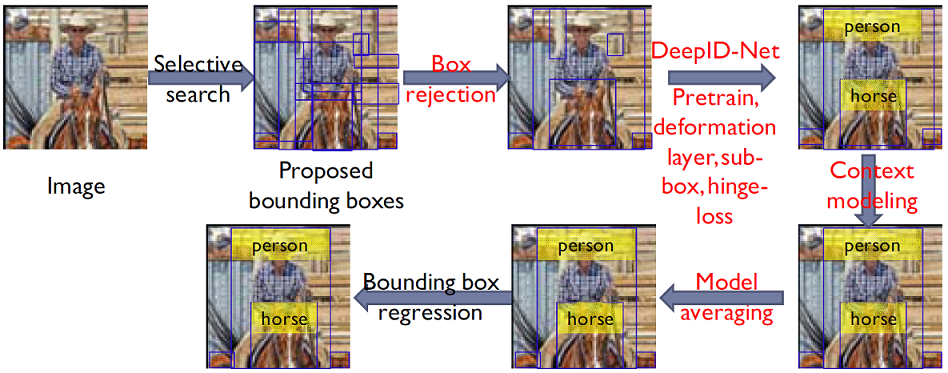

Introduction
The work uses ImageNet classification training set (1000 classes) to pre-train features, and fine tunes features on ImageNet detection training set (200 classes). This detection work is based on deep CNN with proposed new deformation layers, feature pre-training strategy, sub-region pooling and model combination. The effectiveness of learning deformation models of object parts has been proved in object detection by many existing non-deep-learning detectors, e.g. [a]. However, it is missed in current deep learning models. In deep CNN models, max pooling and average pooling are useful in handling deformation but cannot learn the deformation penalty and geometric model of object parts. We design the deformation layer for deep models so that the deformation penalty of objects can be learned by deep models. The deformation layer was first proposed in our recently published work [b], which showed significant improvement in pedestrian detection. In this submission, we extend it to general object detection on ImageNet. In [b], the deformation layer was only applied to a single level corresponding to body parts, while in this work the deformation layer was applied to every convolutional layer to capture geometric deformation at all the levels. In [b], it was assumed that a pedestrian only has one instance of a body part, so each part filter only has one optimal response in a detection window. In this work, it is assumed that an object has multiple instances of body part (e.g. a building has many windows), so each part filter is allowed to have multiple response peaks in a detection window. This new model is more suitable for general object detection.
The whole detection pipeline is much more complex than [b]. In addition to the above improvement, we also added several new components in the pipeline, including feature pre-training on the ImageNet classification dataset (objective function is the image classification task), feature fine-tuning on the ImageNet detection dataset (objective function is the object detection task), a proposed new sub-region pooling step, contextual modeling (which uses the whole image prediction scores over 1000 classes as contextual features to combine with features extracted from a detection window with deep CNN), SVM classification by using the extracted features. We also adopted bounding box regression [c].
A new sub-region pooling strategy is proposed. It divides the detection window into sub-regions, and applies max-pooling or average pooling across feature vectors extracted from different sub-regions. It improves the performance and also increases the model diversity.Different from the state-of-the-art deep learning detection framework [c], which pretrain the net on ImageNet classification data (1000 classes), We proposed a new strategy of doing pre-training on the ImageNet classification data (1000 classes), such that the pre-trained features are much more effective on the detection task and with better discriminative power on object localization.
By changing the configuration of each component of the detection pipeline, multiple models with large diversity are generated. Multiple models are automatically selected and combined to generate the final detection result. We have submitted the results of five different approaches. The first two results report the best performance to be achieved with a single model. Their difference is whether using contextual features from image classification or not. The remaining three results report the best performance to be achieved with model combination. Their differences are using contextual modeling or not, and whether using validation 2 dataset from ImageNet as part of training or not.
Contribution Highlights
- Region rejection. Save feature extraction by about 10 times, slightly improve map (~1%).
- A new pretraining scheme for generic object detection.
- A unified deep model for jointly learning feature extraction, a part deformation model, classification. With the deep model, these components interact with each other in the learning process, which allows each component to maximize its strength when cooperating with others .
- We enrich the operation in deep models by incorporating the generalized deformation layer into the convolutional neural networks (CNN). With this layer, various deformation handling approaches can be applied to our deep model.
- The features are learned from pixels through interaction with deformation models . Such interaction helps to learn more discriminative features.
- Hinge loss. Save feature computation time and lightly improve map.
- A new model averaging investigation for deep models. Different model, training scheme with high diversity
- Multi-stage Deep-id Net.
- A new model averaging investigation for deep models.
Slides
Citation
Code (Available soon)
Code on Google Drive (available soon)