Human Attribute Recognition by Deep Hierarchical Contexts
Yining Li, Chen Huang, Chen Change Loy, and Xiaoou Tang
Department of Informaiton Engineering, The Chinese University of Hong Kong
European Conference on Computer Vision (ECCV) 2016
Yining Li, Chen Huang, Chen Change Loy, and Xiaoou Tang
Department of Informaiton Engineering, The Chinese University of Hong Kong
European Conference on Computer Vision (ECCV) 2016
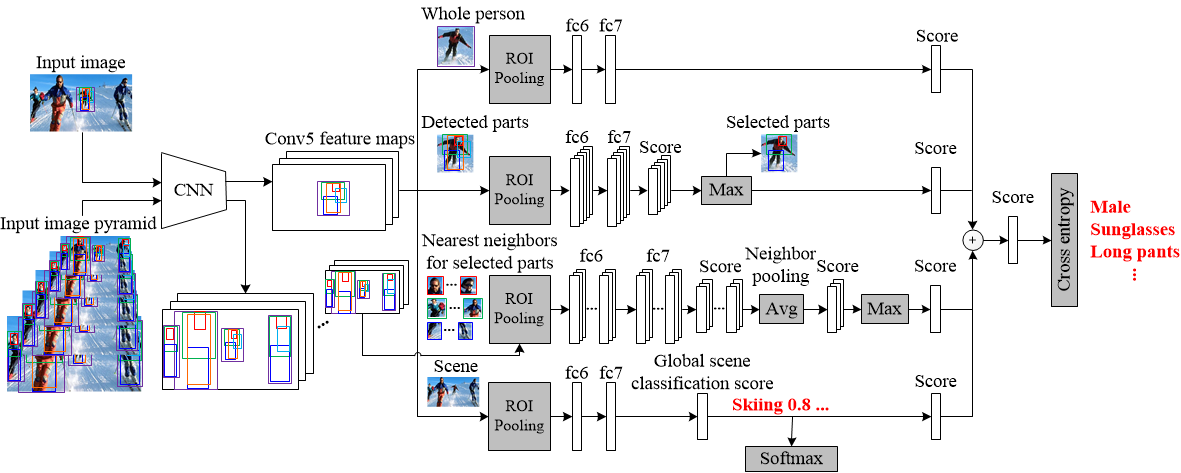
We present an approach for recognizing human attributes in unconstrained settings. We train a Convolutional Neural Network (CNN) to select the most attribute-descriptive human parts from all poselet detections, and combine them with the whole body as a pose-normalized deep representation. We further improve by using deep hierarchical contexts ranging from human-centric level to scene level. Human-centric context captures human relations, which we compute from the nearest neighbor parts of other people on a pyramid of CNN feature maps. The matched parts are then average pooled and they act as a similarity regularization. To utilize the scene context, we re-score human-centric predictions by the global scene classification score jointly learned in our CNN, yielding final scene-aware predictions. To facilitate our study, a large-scale WIDER Attribute dataset is introduced with human attribute and image event annotations, and our method surpasses competitive baselines on this dataset and other popular ones.
The mean AP (%) on Berkeley Attributes of People dataset, HAT dataset and WIDER Attribute dataset:
| Method | Berkeley | HAT | WIDER Attribute |
|---|---|---|---|
| PANDA | 79.0 | - | - |
| ACNH | 80.0 | 66.2 | - |
| R-CNN | 87.8 | 76.3 | 80.0 |
| R*CNN | 89.2 | 76.4 | 80.5 |
| Deep Part | 89.5 | - | - |
| Our Baseline | 90.8 | 76.7 | 80.5 |
| Our Full Model | 92.2 | 78.0 | 81.3 |
WIDER Attribute is a large-scale human attribute dataset. It contains 13789 images belonging to 30 scene categories, and 57524 human bounding boxes each annotated with 14 binary attributes.
Download: [Images (Google Drive)], [Annotations]

@inproceedings{li2016human,
author = {Li, Yining and Huang, Chen and Loy, Chen Change and Tang, Xiaoou},
title = {Human Attribute Recognition by Deep Hierarchical Contexts},
booktitle = {European Conference on Computer Vision},
year = {2016}
}