Learning to Disambiguate by Asking Discriminative Questions
Yining Li1,
Chen Huang2,
Xiaoou Tang1, and
Chen Change Loy1
1Department of Informaiton Engineering, The Chinese University of Hong Kong
2Robotics Institute, Carnegie Mellon University
IEEE International Conference on Computer Vision (ICCV) 2017
[Full Paper] [Dataset]
Abstract
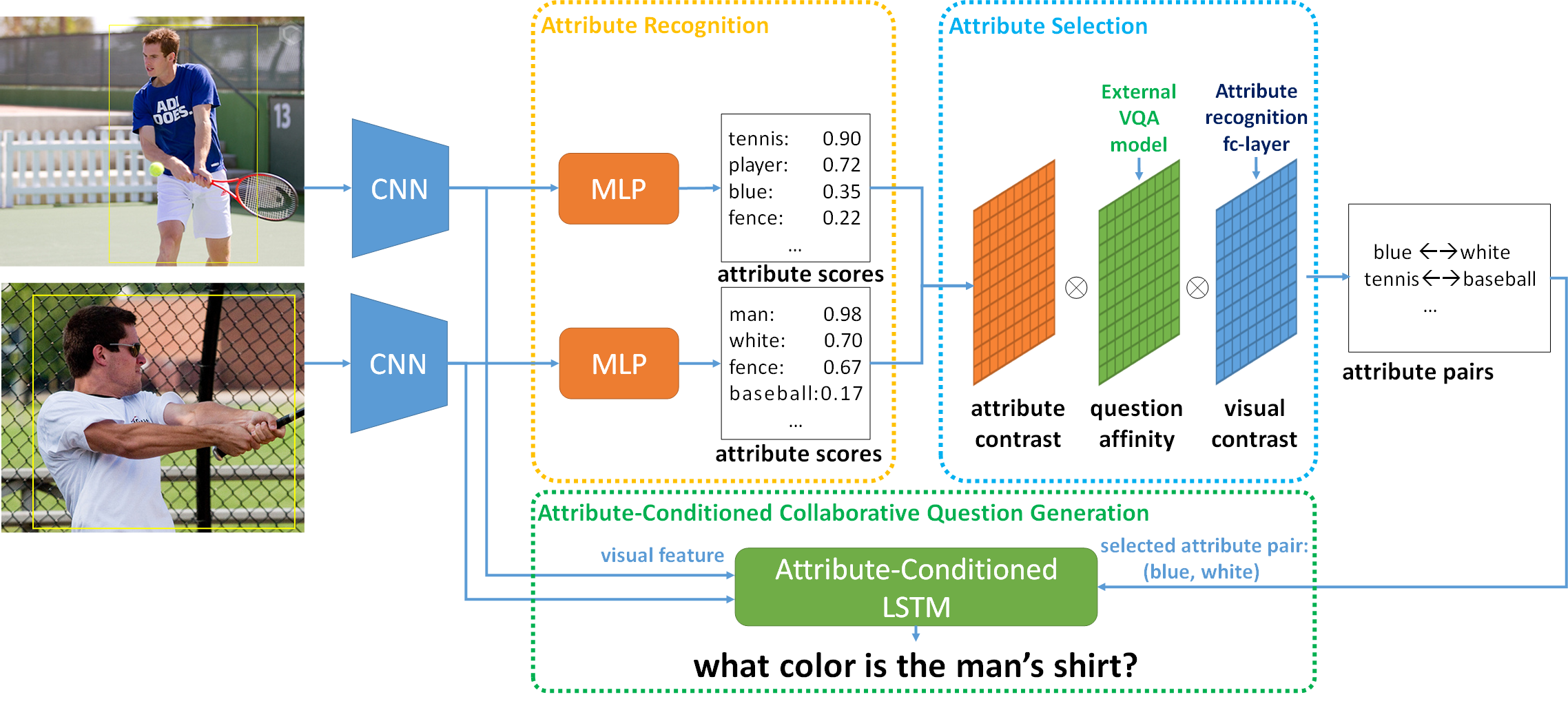
The ability to ask questions is a powerful tool to gather information in order to learn about the world and resolve ambiguities. In this paper, we explore a novel problem of generating discriminative questions to help disambiguate visual instances. Our work can be seen as a complement and new extension to the rich research studies on image captioning and question answering. We introduce the first large-scale dataset with over 10,000 carefully annotated images-question tuples to facilitate benchmarking. In particular, each tuple consists of a pair of images and 4.6 discriminative questions (as positive samples) and 5.9 non-discriminative questions (as negative samples) on average. In addition, we present an effective method for visual discriminative question generation. The method can be trained in a weakly supervised manner without discriminative images-question tuples but just existing visual question answering datasets. Promising results are shown against representative baselines through quantitative evaluations and user studies.