Face alignment is a very fundamental problem in computer vision. Applications of face alignment range from face tracking, human computer interaction, face recognition and modeling, to face cartoon animation. With the explosive increase in personal and web photos nowadays, a fully automatic, highly efficient and robust face alignment method is in demand. Although great progress has been made, face alignment remains a difficult problem due to the following challenges: a) they often undergo both rigid transformations and non-rigid deformations. b) Different faces of different people have dramatically different appearances under a variety of illumination, pose and partial occlusions conditions. To address these challenges, we have been developing many robust algorithms for face alignment.
Highlights

Hierarchical Face Parsing via Deep Learning
P. Luo, X. Wang, and X. Tang, in Proceedings of IEEE Computer Society Conference on Computer Vision and Patter Recognition (CVPR) 2012
This paper investigates how to parse (segment) facial components from face images which may be partially occluded.
We propose a novel face parser, which recasts segmentation of face components as a cross-modality data transformation problem, i.e., transforming an image patch to a label map.
Specifically, a face is represented hierarchically by parts, components, and pixel-wise labels.
With this representation, our approach first detects faces at both the part- and component-levels, and then computes the pixelwise label maps

Joint Face Alignment with a Generic Deformable Face Model.
C. Zhao, W. K. Cham and X. Wang. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (Poster, CVPR 2011)
As having multiple images of an object is practically convenient nowadays, to jointly align them is important for subsequent studies and a wide range of applications. In this paper, we propose a model-based approach to jointly align a batch of images of a face undergoing a variety of geometric and appearance variations. The principal idea is to model the non-rigid deformation of a face by means of a learned deformable model. Different from existing model-based methods such as Active Appearance Models, the proposed one does not rely on an accurate appearance model built from a training set. We propose a robust fitting method that simultaneously identifies the appearance space of the input face and brings the images into alignment. The experiments conducted on images in the wild in comparison with competing methods demonstrate the effectiveness of our method in joint alignment of complex objects like human faces.
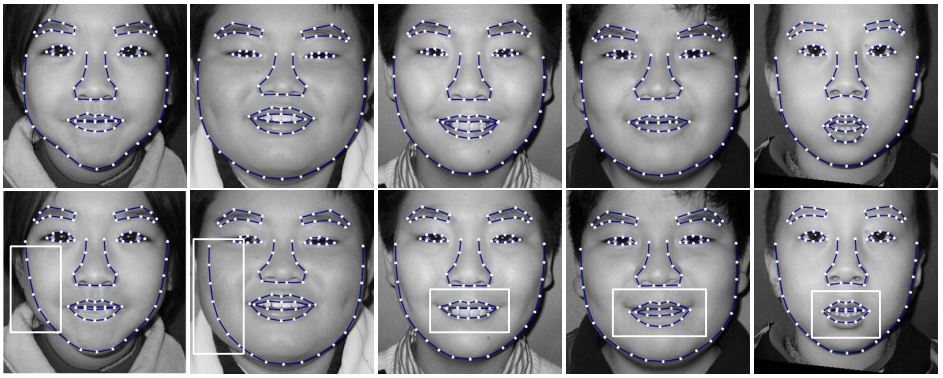
Accurate Face Alignment using Shape Constrained Markov Network.
L. Liang, F. Wen, Y. Xu, X. Tang and H. Shum. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (Poster, CVPR 2006)
In this paper, we present a shape constrained Markov network for accurate face alignment. The global face shape is defined as a set of weighted shape samples which are integrated into the Markov network optimization. These weighted samples provide structural constraints to make the Markov network more robust to local image noise. We propose a hierarchical Condensation algorithm to draw the shape samples efficiently. Specifically, a proposal density incorporating the local face shape is designed to generate more samples close to the image features for accurate alignment, based on a local Markov network search. A constrained regularization algorithm is also developed to weigh favorably those points that are already accurately aligned. Extensive experiments demonstrate the accuracy and effectiveness of our proposed approach.
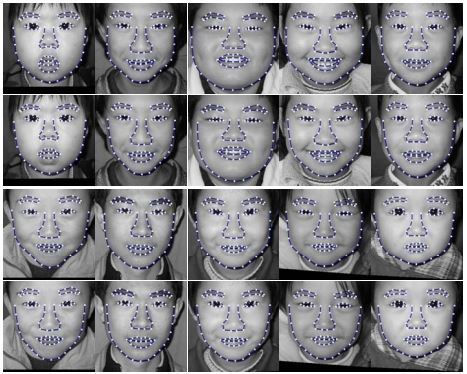
An Integrated Model for Accurate Shape Alignment.
L. Liang, F. Wen, X. Tang and Y. Yu. In Proceedings of European Conference on Computer Vision(Poster, ECCV 2006)
In this paper, we propose a two-level integrated model for accurate face shape alignment. At the low level, the shape is split into a set of line segments which serve as the nodes in the hidden layer of a Markov Network. At the high level, all the line segments are constrained by a global Gaussian point distribution model. Furthermore, those already accurately aligned points from the low level are detected and constrained using a constrained regularization algorithm. By analyzing the regularization result, a mask image of local minima is generated to guide the distribution of Markov Network states, which makes our algorithm more robust. Extensive experiments demonstrate the accuracy and effectiveness of our proposed approach.

A Probabilistic Model for Robust Face Alignment in Videos.
W. Zhang, Y. Zhou, X. Tang and J. Deng. In Proceedings of IEEE Conference on Image Processing(Poster, ICIP 2005)
A new approach for localizing facial structure in videos is proposed in this paper by modeling shape alignment dynamically. The approach makes use of the spatial-temporal continuity of videos and incorporates it into a statistical shape model which is called Constrained Bayesian Tangent Shape Model (C-BTSM). Our model includes a prior 2D shape model learnt from labeled examples, an observation model obtained from observation in the current input image, and a constraint model derived from the prediction by the previous frames. By modeling the prior, observation and constraint in a probabilistic framework, the task of aligning shape in each frame of a video is performed as a procedure of MAP parameter estimation, in which the pose and shape parameters are recovered simultaneously. Experiments on low quality videos from web cameras are provided to demonstrate the robustness and accuracy of our algorithm.

A Bayesian Mixture Model for Multi-View Face Alignment.
Y. Zhou, W. Zhang, X. Tang and H. Shum. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition(Poster, CVPR 2005)
For multi-view face alignment, we have to deal with two major problems: 1. the problem of multi-modality caused by diverse shape variation when the view changes dramatically; 2. the varying number of feature points caused by self-occlusion. Previous works have used nonlinear models or view based methods for multi-view face alignment. However, they either assume all feature points are visible or apply a set of discrete models separately without a uniform criterion. In this paper, we propose a unified framework to solve the problem of multi-view face alignment, in which both the multi-modality and variable feature points are modeled by a Bayesian mixture model. We first develop a mixture model to describe the shape distribution and the feature point visibility, and then use an efficient EM algorithm to estimate the model parameters and the regularized shape. We use a set of experiments on several datasets to demonstrate the improvement of our method over traditional methods.