In this project, Harris Corner Detection and Harris-Laplacian Detection are studied in the keypoint/feature detection stage. And two feature descriptors, 5-by-5 patch intensity descriptor and Fourier descriptor are compared in image matching. Besides, Adaptive Non-Maximal Suppression is used here to make the keypoint distribution more even in the image.
Based the observation that the the autocorrelation have a larger response in areas containing corners than those that are flatten, Harris and Stephens introduced the both well-know and well-used Harris Corner detection. Instead of re-iterating the algorithm here, I will present the details to my implementation of Harris Corner detection.
![]()
Regular Harris Corner OR Multi-Scale Harris Corner
In the experiment I found that scale has a serious affection on Harris Corner Detection, which make it necessary to find some algorithm to fulfill scale invariance. Multi-Scale Harris Corner Detection is a possible way to solve this problem. However, K. Mikolajczyk and C. Schmid compared different scale representation functions and found that Harris-Laplacian performs best in scale invariance. So, instead of the Multi-Scale Harris Corner Detection (pls be referred to Wiki), Harris-Laplacian is used to achieve the scale invariant object.
Parameters in Regular Harris Corner
the gray level of an image is converted to [0,1)
integration scale of the Gaussian Function = 0.8
size of the window when determining the local maxima = 5 * 5
threshold for ignoring low response = 0.01
Experiments img1 img2 img5 img6
















It is well known that Harris Corner Detection has rotation invariance, partial intensity affine invariance, but it is not scale invariant. Even the keypoint number is affected by the scale. The image "bikes" has a increment scale change from image1 to image6, and as a result the keypoint number detected decreases sharply. This makes it necessary to find some scale invariance detection.
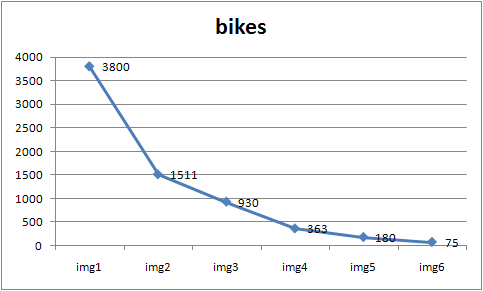
Keypoint Number decreases as scale increases
Besides the scale, there is another phenomenon about which we may be not very satisfied. Images in the last row have far more keypoints than images in other rows though the parameters are all the same for them and for other kinds of images. It is possible to design some adaptive parameters to solve this problem, for example we can set parameters with the variance of the image. Here, the Adaptive Non-Maximal Suppression used in Multi-Image Matching using Multi-Scale Oriented Patches (M. Brown, Richard Szeliski and Simon Winder) is implemented.
![]()
Parameters
robust parameter c = 0.9
Keypoint Number (This parameter can be replaced by the minimum of the "minimum suppression radius")
Experiments




keypoint number = 3000 keypoint number = 2000 keypoint number = 1000 keypoint number = 500
In Scale & Affine Invariant Interest Point Detectors (IJCV2004), K. Mikolajczyk and C. Schmid introduced the Harris-Corner Detection. In my implementation, I found that it took too much time to build the scale space and to compute the normalized Laplacian of Gaussian (LoG). So here I use Difference of Gaussian (DoG) to simulate LoG. As Lowe proved in Distinctive Image Features from Scale-Invariant Keypoints (IJCV2004), DoG is a fair approximation of LoG while saving a lot time.
Create scale space. Sampling of the scale is based on sigma_n = pow(factor, n) * sigma_0. (here sigma_0 = 1.6, factor = 1.2)
Harris-Corner detection on every scale. The integration scale of Harris Corner equals to current image scale sigma_n.
Adaptive Non-Maximal Suppression, to keep at most 1000 points for each scale level.
Compute DoG images, so we get a stack of DoG images.
Find scale extrema. The output of step 3 will be taken as the input points, to check if they are the extrema in the scale space.
Label keypoints in the first scale level with red color, keypoints in the second scale level with green color, keypoints in the third level with blue color.




Known the keypoint position, it is now able to get the feature description using the neighbor area of the keypoint. In Harris-Laplacian, the scale information should also be considered in when design the feature description.
The first description is to simply align the 5-by-5 square window centered at the keypoint into a 1D descriptor. It is a fairly good descriptor without losing any information, and is translation invariant. By normalizing the descriptor, it is also possible to achieve more or less illumination invariance. And the Harris-Laplacian detection guaranteed its scale invariance.
The second one is designed for a stronger requirement, i.e. rotation invariance. SIFT realized rotation invariant by finding out the dominant orientation and making a circular shift. The 8*8 patch of bias/gain normalized intensity descriptor used in Multi-Image Matching using Multi-Scale Oriented Patched (CVPR05) also involves the computation of the dominant orientation. I try to achieve rotation invariance without explicitly computing of dominant orientation by using Fourier Transformation.
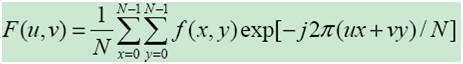
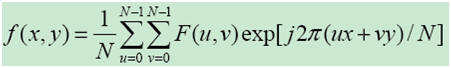
The translation and rotation in spatial domain will cause phase variation in frequency domain, while has no affection on the magnitude,
![]()
![]()
So, if we keep only the magnitude part, the "same" patches with different dominant orientations will has the same descriptor, which makes the rotation invariance a simple task. Besides, the zero-frequency (u = v = 0) of Fourier Transformation is the average of the patch intensity. Usually the zero-frequency is used as the normalization factor. So finally the Fourier Descriptor is as below,
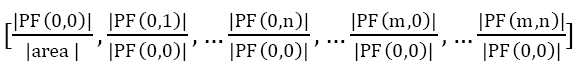
Comparing to feature detection and feature description, the ways of feature matching are not that important. I use the two simple methods recommended in the course webpage. Time allowed, I may test RANSAC in next project.
Use a threshold on the match score
compute the score ratio of the best match and second best match (1-NN / 2-NN)
It's time for our evaluation of the features. Using Harris-Laplacian as the feature detection, 5*5 intensity descriptor, Fourier descriptor, and SIFT are compared under the 2nd feature matching method with the ratio equaling to 0.8, as recommended by Lowe. (In other words, the results for SIFT here should be optimal, while for 5*5 intensity descriptor and Fourier descriptor, a big improvement is still possible.) The raw result has been posted as below. And next I'll give some statistics about the result.
| average error---matching point number | |||
| bikes | 5*5 | Fourier | SIFT |
| img1-img2 | 226.668603 ---- 743 | 32.091738 ---- 873 | 34.654367 -- 2039 |
| img1-img3 | 239.175283 ---- 707 | 34.765250 ---- 834 | 35.403724 -- 1910 |
| img1-img4 | 300.506786 ---- 659 | 61.482886 ---- 663 | 66.146809 -- 1474 |
| img1-img5 | 337.798843 ---- 655 | 134.514733 ---- 451 | 93.676673 -- 1216 |
| img1-img6 | 384.775677 ---- 699 | 221.437077 ---- 321 | 135.586715 -- 1033 |
| graf | 5*5 | Fourier | SIFT |
| img1-img2 | 320.720052 ---- 684 | 322.806371 ---- 287 | 54.962539 -- 1120 |
| img1-img3 | 293.248058 ---- 725 | 261.970607 ---- 251 | 79.074253 -- 755 |
| img1-img4 | 323.637529 ---- 694 | 316.018941 ---- 233 | 178.672469 -- 446 |
| img1-img5 | 305.218881 ---- 731 | 299.077971 ---- 266 | 287.884198 -- 382 |
| img1-img6 | 321.679589 ---- 731 | 308.929170 ---- 235 | 325.045539 -- 314 |
| leuven | 5*5 | Fourier | SIFT |
| img1-img2 | 174.574909 ---- 703 | 27.611283 ---- 788 | 22.313877 -- 1272 |
| img1-img3 | 217.170730 ---- 709 | 55.397088 ---- 682 | 24.653266 -- 1197 |
| img1-img4 | 238.180522 ---- 687 | 66.686421 ---- 588 | 32.560914 -- 1127 |
| img1-img5 | 248.422157 ---- 663 | 98.162596 ---- 508 | 30.405703 -- 1057 |
| img1-img6 | 273.771324 ---- 657 | 133.476097 ---- 450 | 46.496595 -- 980 |
| wall | 5*5 | Fourier | SIFT |
| img1-img2 | 283.317168 ---- 738 | 47.069230 ---- 666 | 24.923635 -- 1695 |
| img1-img3 | 309.671504 ---- 714 | 93.151045 ---- 463 | 44.376893 -- 1463 |
| img1-img4 | 343.991918 ---- 679 | 215.735849 ---- 296 | 66.805623 -- 1017 |
| img1-img5 | 371.159098 ---- 681 | 347.989133 ---- 206 | 135.467476 -- 572 |
| img1-img6 | 395.142245 ---- 669 | 375.518487 ---- 220 | 351.852514 -- 270 |
This is the average pixel distance of the matching points.
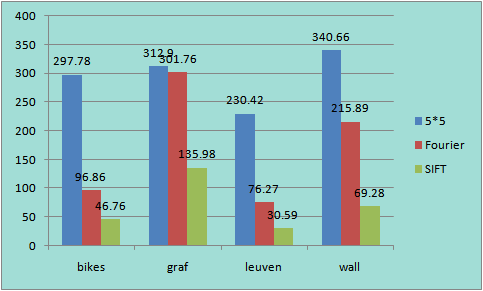
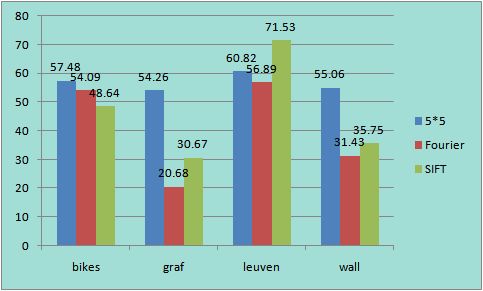
Average Matching Error Average Matching Features / Feature Number in Query Image
We can get both average error and average matched features by using command "project2 benchmark dir". However, different algorithms will generate different numbers of features. SIFT may have 3000 around keypoints in my experiment, while in Multi-Image Matching using Multi-Scale Oriented Patches (M. Brown, Richard Szeliski and Simon Winder) only 500 points are kept. In my Harris-Laplacian algorithm, the number of keypoints is controlled by the parameter of "keypoint_num", and here I kept 1000 points in ANMS. So, I think a better way to compare the matching features is to use the ratio, i.e. matching feature number / all feature number in query image.
Fourier descriptor performs well on "bikes" and "leuven", which proves that it is robust to image blur and illumination changing. With further experiments the performance of Fourier Descriptor is supposed to be improved, even to approach the result of SIFT.
It is also expected that Fourier descriptor would perform better than SIFT under the large degree rotation environment, because Fourier descriptor will be constant regardless of the rotation degree. While SIFT can only handle small degree rotation (less than 30 degree usually).
Besides, the affine transformation in "graf" and "wall" is a disaster for all of the three descriptors, both in the matching point number and the matching accuracy/error. If we have to process images with serious affine transformation, it is necessary to design affine invariant features.
Reference
[1] David G.Lowe, "Distinctive image features from scale-invariant keypoints", International Journal of Computer Vision, 60, 2 (2004), pp. 91 - 110
[2] M.Brown, R. Szeliski and S. Winder, "Multi-Image using multi-scale oriented patches", International Conference on Computer Vision and Pattern Recognition 2005, pages 510 - 517
[3] K. Mikolajczyk and C. Schmid, "Indexing based on scale invariant interest points", International Conference on Computer Vision 2001, pp 525-531
[4] K. Mikolajczyk and C. Schmid, "Scale & Affine interest point detectors", International Journal of Computer Vision 60(1), 63-86, 2004
[5] T. Lindeberg, "Feature detection with automatic scale selection", International Journal of Computer Vision,30(2), pp79-116, 1998
Home Previous: Canny Edge Detection Next: Automatic Panoramaic Mosaic Stitching