Introduction
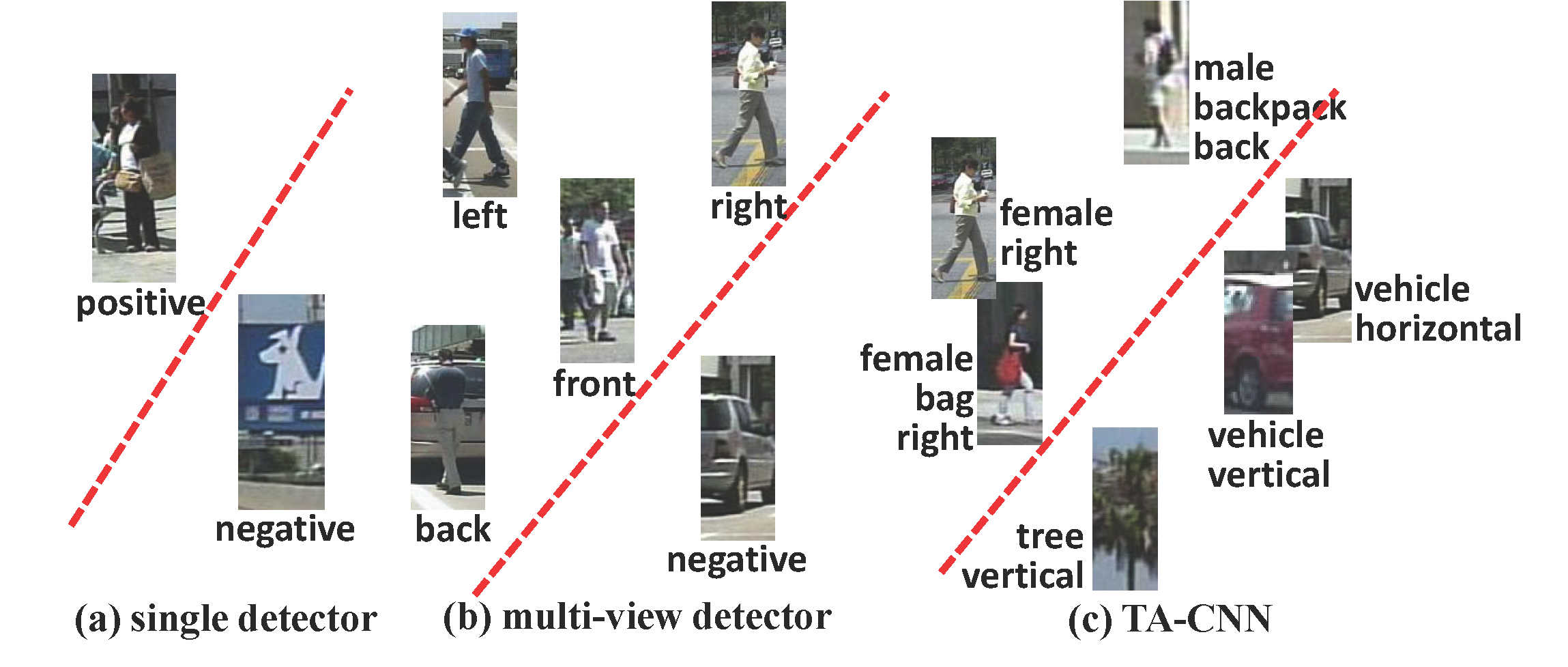
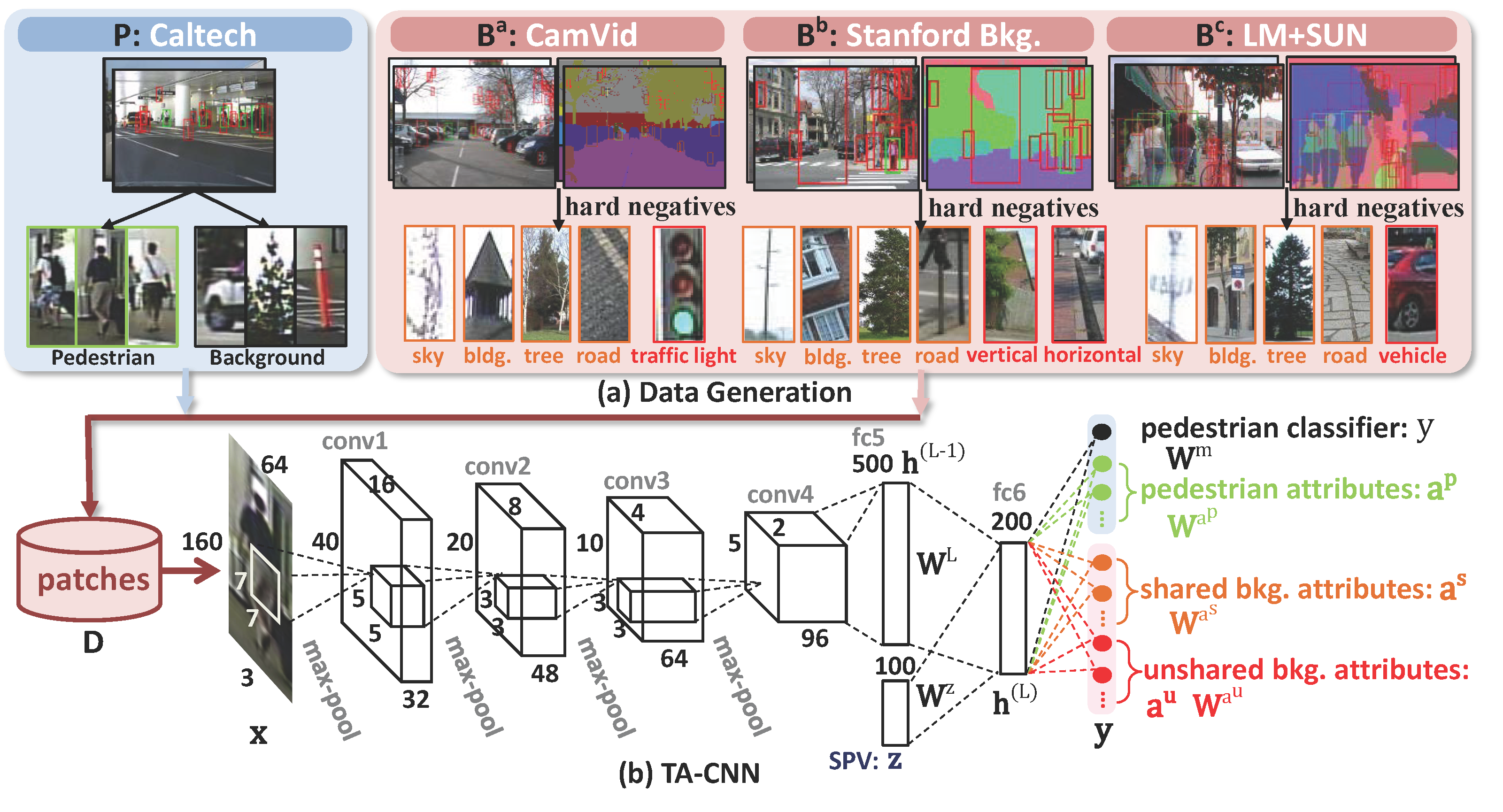
Deep learning methods have achieved great successes in pedestrian detection, owing to its ability to learn discriminative features from raw pixels. However, they treat pedestrian detection as a single binary classification task, which may confuse positive with hard negative samples. To address this ambiguity, this work jointly optimize pedestrian detection with semantic tasks, including pedestrian attributes (e.g. 'carrying backpack') and scene attributes (e.g. `vehicle', `tree', and `horizontal'). Rather than expensively annotating scene attributes, we transfer attributes information from existing scene segmentation datasets to the pedestrian dataset, by proposing a novel deep model to learn high-level features from multiple tasks and multiple data sources. Since distinct tasks have distinct convergence rates and data from different datasets have different distributions, a multi-task deep model is carefully designed to coordinate tasks and reduce discrepancies among datasets. Extensive evaluations show that the proposed approach outperforms the state-of-the-art on the challenging Caltech and ETH datasets where it reduces the miss rates of previous deep models by 17 and 5.5 percent, respectively.
We manually label the pedestrian attributes of Caltech Pedestrian dataset (every 30th frame which follows the standard training and testing protocol).
Contribution Highlights
- Discriminative representation for pedestrian detection is learned by jointly optimizing with semantic attributes, including pedestrian attributes and scene attributes. The scene attributes can be transferred from existing scene datasets without annotating manually.
- Multiple tasks from multiple sources are trained using a single task-assistant CNN (TA-CNN), which is carefully designed to bridge the gaps between different datasets
- We systematically investigate the effectiveness of attributes in pedestrian detection.
Download
Citation
If you use pedestrian attributes labels or detection results, please cite the following papers:
- Y. Tian, P. Luo, X. Wang, and X. Tang. Pedestrian Detection Aided by Deep Learning Semantic Tasks. In CVPR, 2015. PDF
Images
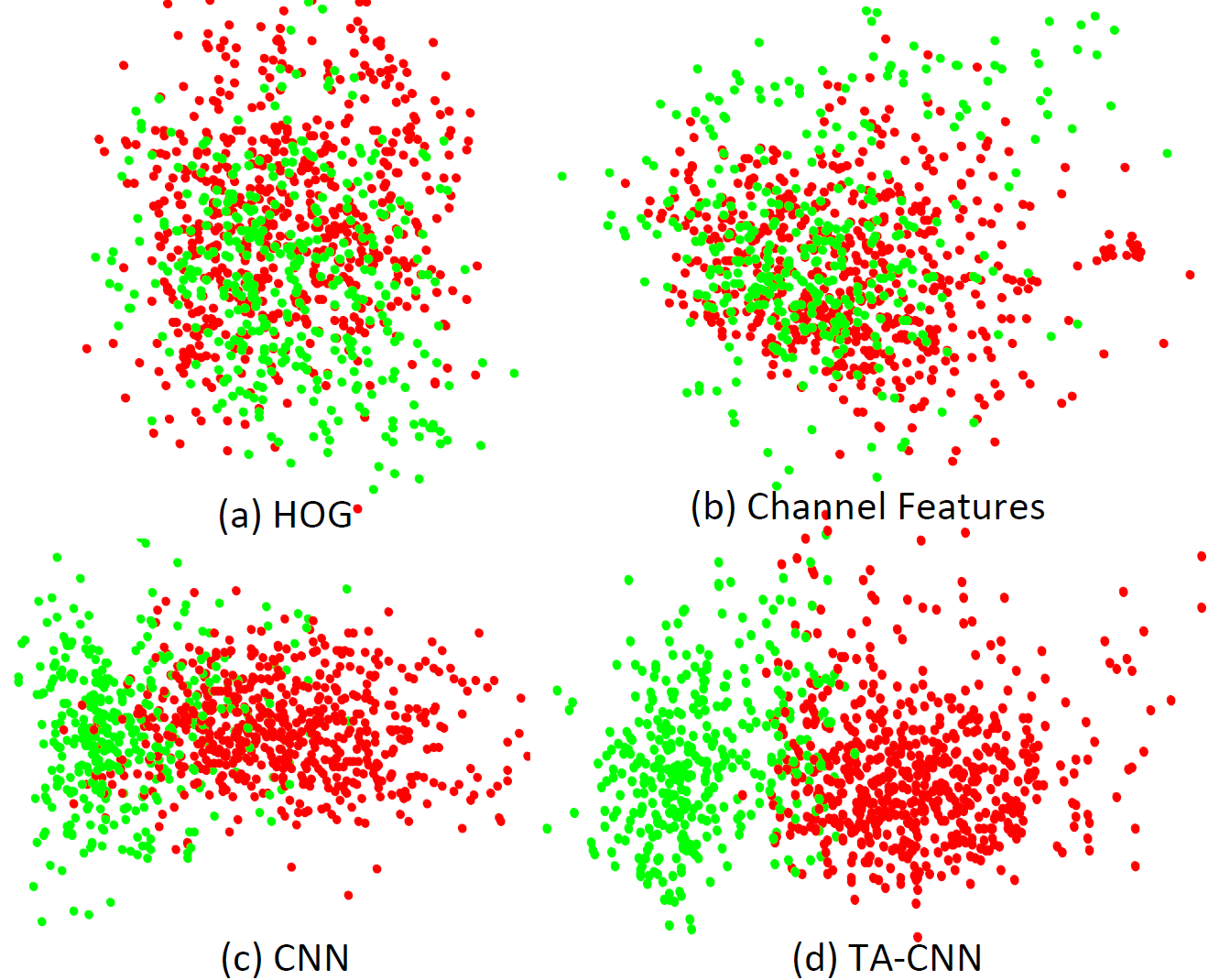
Visualization of 4 types of features for positive and hard negatives on Caltech-Test.
HOG and Channel Features are hand-crafted and not jointly optimized with the classifier, while CNN and TA-CNN are both leaned representations. It is notable that features learned by TA-CNN are more separable than CNN.
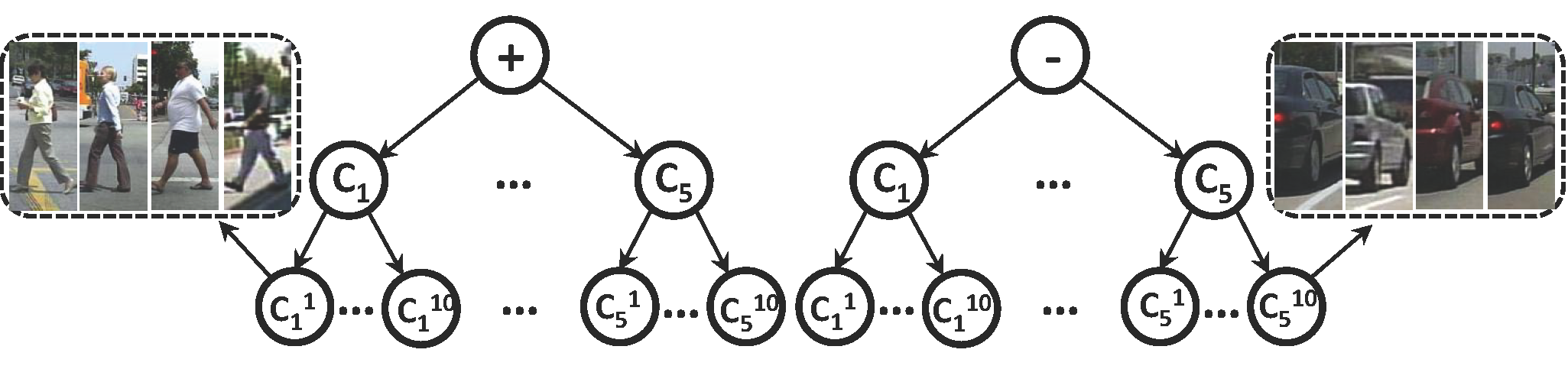
Used as additive information to bridge the visual gaps between the background datasets and the pedestrian dataset
Computation process: (1) Organizing the positive and negative patches of pedestrian dataset into two tree structures by HOG feature clustering. Specifically, each tree partitions patches top-down, and have 3 layers and 50 leaf nodes; (2)SPV of each sample is obtained by concatenating the distances between its HOG feature and the mean HOG feature of each leaf node.
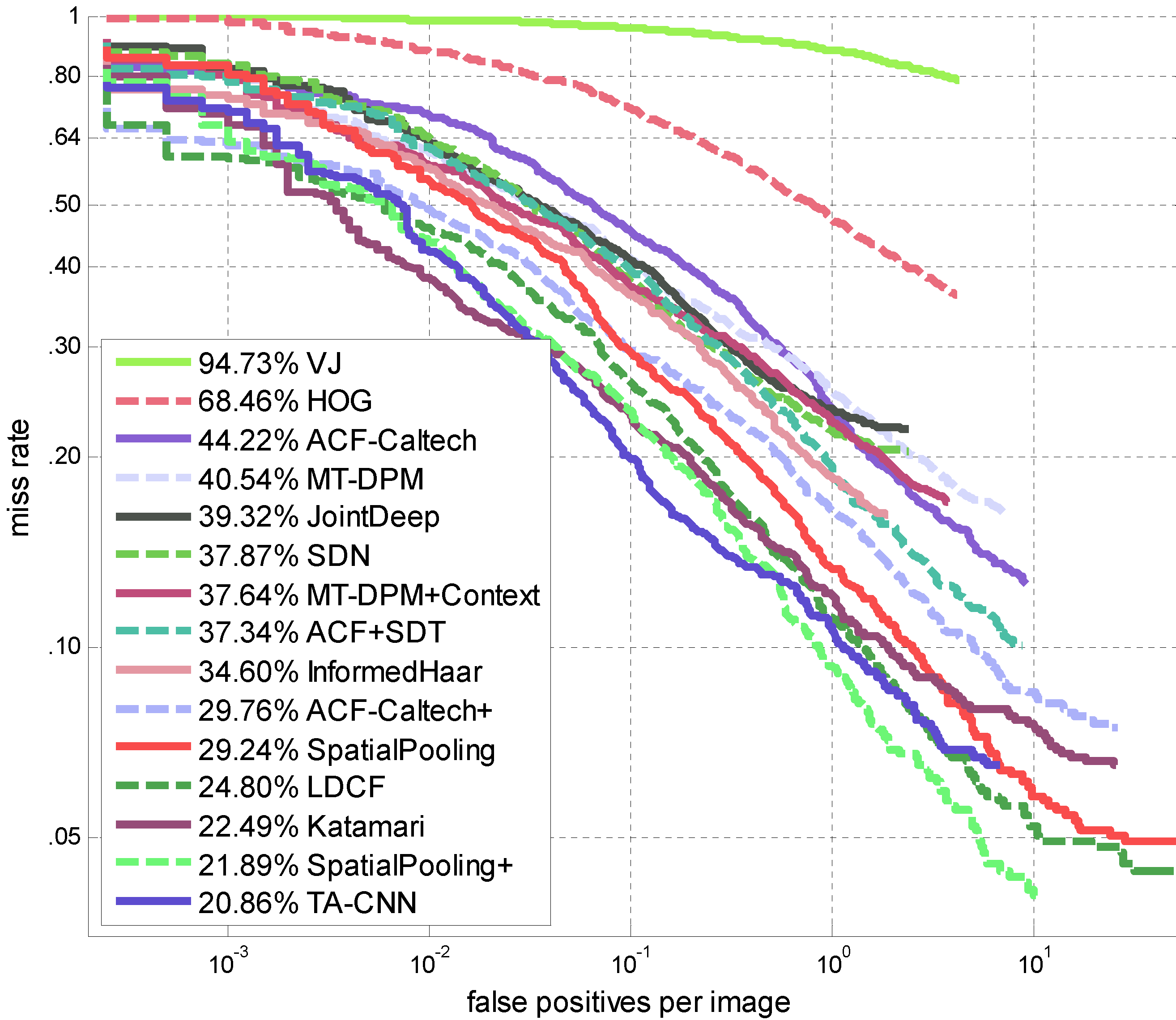
TA-CNN achieves ~21% average miss rate on Caltech reasonable protocol
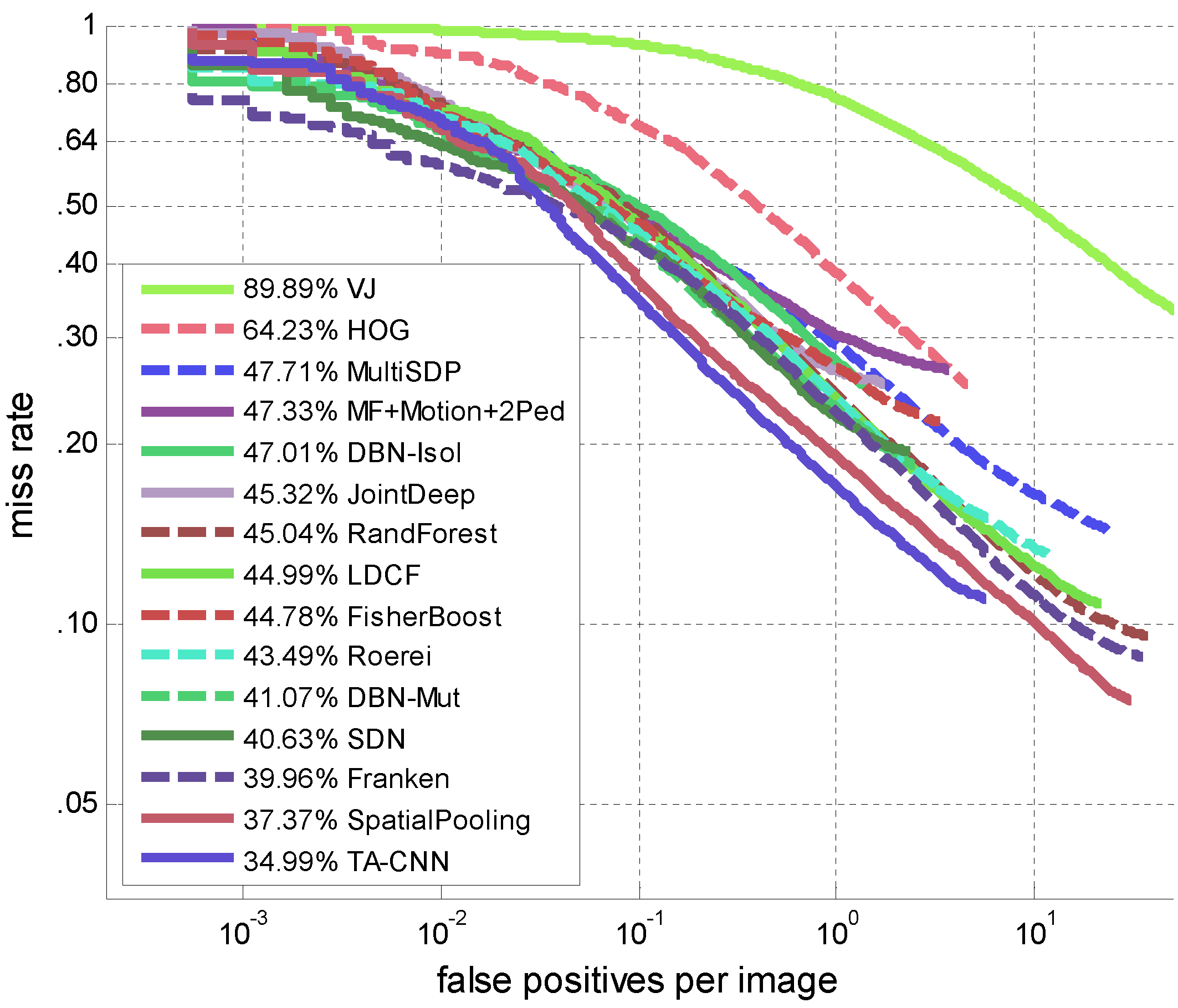
TA-CNN achieves ~35% average miss rate on ETH reasonable protocol