
Introduction
We propose a new Deep Decompositional Network (DDN) for parsing pedestrian images into semantic regions, such as hair, head, body, arms, and legs. Unlike existing methods based on template matching or Bayesian inference, our approach directly maps low-level visual features to the label maps of body parts with DDN, which is able to accurately estimate complex pose variations with good robustness to occlusions and background clutters. DDN jointly estimates occluded regions and segments body parts by stacking three types of hidden layers: occlusion estimation layers, completion layers, and decomposition layers. Experimental results show that our approach achieves better segmentation accuracy than the state-of-the-art methods on pedestrian images with or without occlusions.
This paper provides a large scale benchmark human parsing dataset that includes 3673 annotated samples collected from 171 surveillance videos. It is 20 times larger than existing public datasets.
Download
Citation
If you use our codes or dataset, please cite the following papers:
- P. Luo, X. Wang, and X. Tang, Pedestrian Parsing via Deep Decompositional Neural Network, in Proceedings of IEEE International Conference on Computer Vision (ICCV) 2013 PDF
Images

DDN stacks three types of hidden layers: occlusion estimation layers, completion layers, and decomposition layers. The occlusion estimation layers estimate a binary mask, indicating which part of a pedestrian is invisible. The completion layers synthesize low-level features of the invisible part from the original features and the occlusion mask. The decomposition layers directly transform the synthesized visual features to label maps.

Parsing results on the Penn-Fudan dataset.
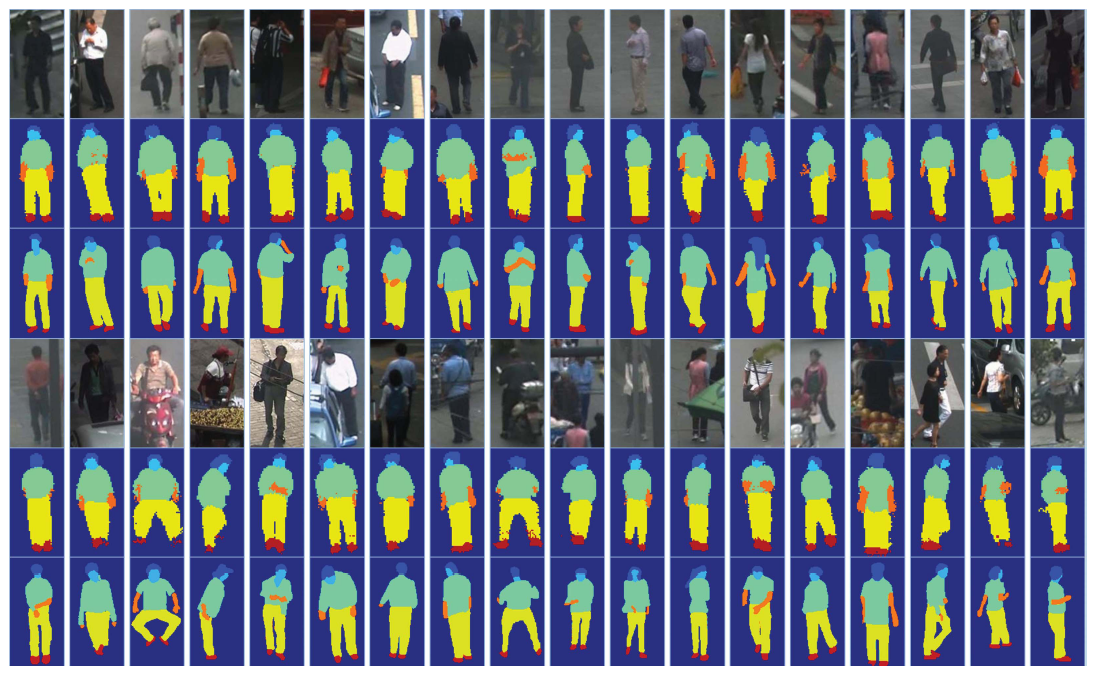
Parsing results on the PPSS dataset. The above three rows are for the unoccluded pedestrians, and the below for the occluded pedestrians, where the images, predicted label maps and ground truthes are shown respectively.