
Introduction
Face recognition with large pose and illumination variations is a challenging problem in computer vision. This paper addresses this challenge by proposing a new learning-based face representation: the face identity-preserving (FIP) features. Unlike conventional face descriptors, the FIP features can significantly reduce intra-identity variances, while maintaining discriminativeness between identities. Moreover, the FIP features extracted from an image under any pose and illumination can be used to reconstruct its face image in the canonical view. This property makes it possible to improve the performance of traditional descriptors, such as LBP and Gabor, which can be extracted from our reconstructed images in the canonical view to eliminate variations.
In order to learn the FIP features, we carefully design a deep network that combines the feature extraction layers and the reconstruction layer. The former encodes a face image into the FIP features, while the latter transforms them to an image in the canonical view. Extensive experiments on the large MultiPIE face database demonstrate that it significantly outperforms the state-of-the-art face recognition methods.
Download
- We provide a demo code, which shows how the frontal-view face image of a query face image is reconstructed. Demo Code
- DATA: Five facial landmarks (two eyes, nose, and mouth) of the images in the MultiPIE dataset are manully labeled. Download
- More source code. Available soon
Citation
If you use our codes or dataset, please cite the following papers:
- Z. Zhu*, P. Luo*, X. Wang, and X. Tang, Deep Learning Identity Preserving Face Space, in Proceedings of IEEE International Conference on Computer Vision (ICCV) 2013 (* indicates equal contribution) PDF
Images
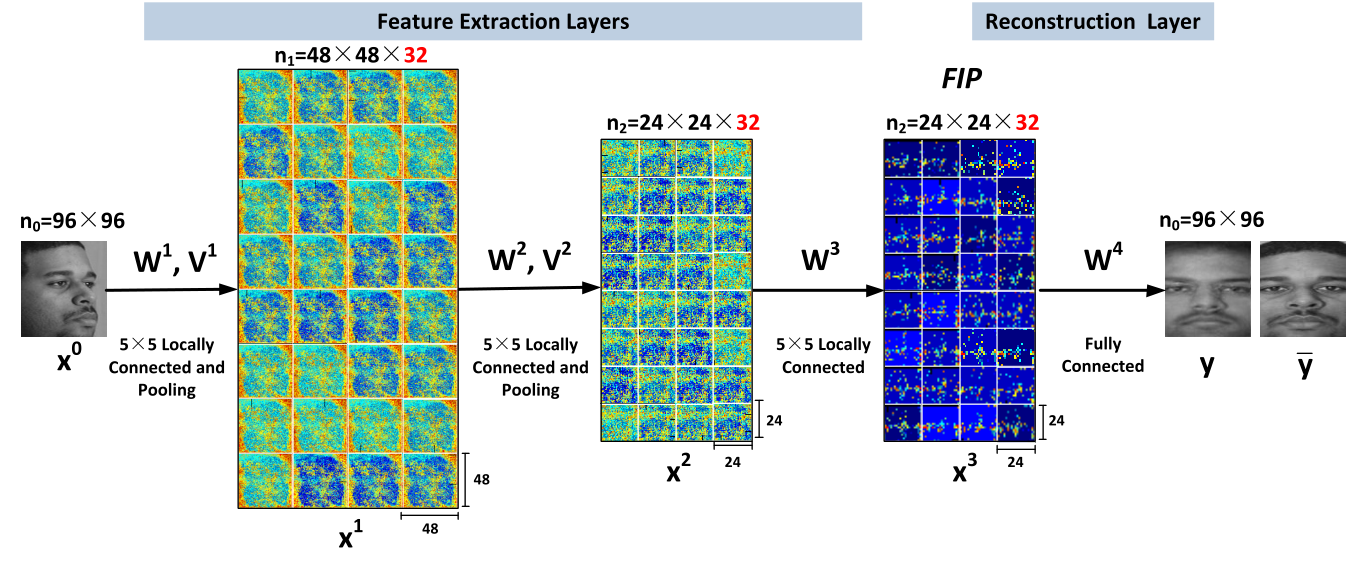
The network combines the feature extraction layers and reconstruction layer. The feature extraction layers include three locally connected layers and two pooling layers. They encode an input face x0into FIP features x3. x1, x2 are the output feature maps of the first and second locally connected layers. FIP features can be used to recover the face image y in the canonical view. y is the ground truth.
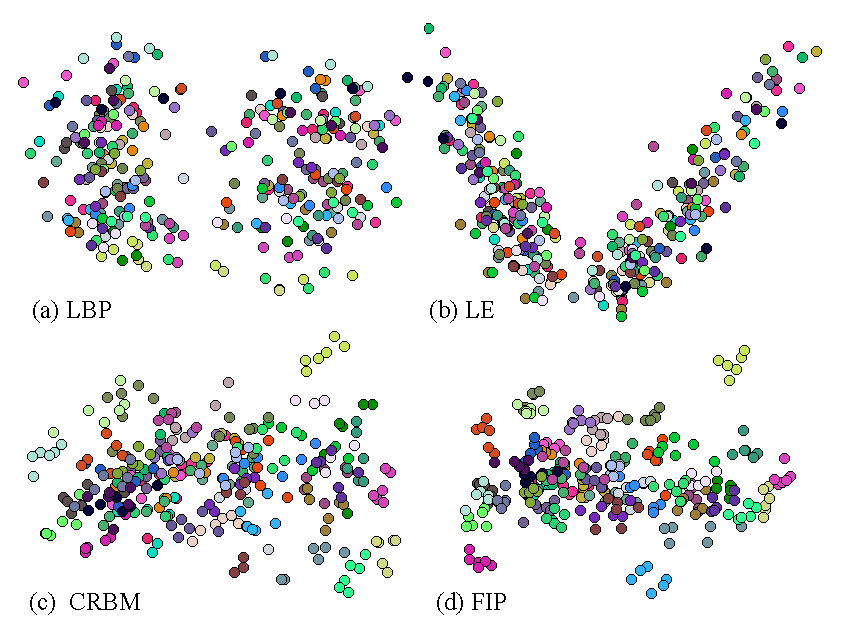
The LBP (a), LE (b), CRBM (c), and FIP (d) features of 50 identities, each of which has 6 images in different poses and illuminations are projected into two dimensions using Multidimensional scaling (MDS). Images of the same identity are visualized in the same color. It shows that FIP has the best representative power.

For each identity, we select its images with 6 poses and arbitrary illuminations. The reconstructed frontal face images under neutral illumination are visualized below. We clearly see that our method can remove the effects of both poses and illuminations, and retains the intrinsic face shapes and structures of the identity.